Nel precedente post vi ho proposto una rapida comparativa tra SQL Azure e l'Azure Table Storage, tentando di analizzare punti di forza e di debolezza di entrambe queste tecnologie destinate prevalentemente a cui sviluppa sistemi cloud based su Windows Azure.
Quest'oggi vi parlerò di un design pattern denominato Command Query Responsibility Segregation che si sposa ottimamente con le caratteristiche del cloud, in particolare per lo sviluppo di sistemi che richiedano una scalabilità orizzontale elevatissima (diciamo potenzialmente infinita). Per analizzare questo design pattern partiamo da un esempio di classica architettura client-server.
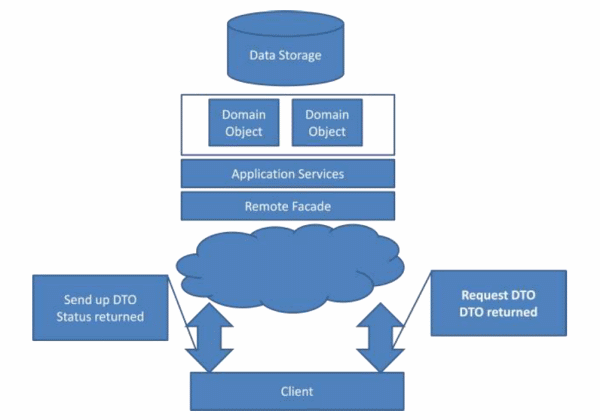
Si tratta della classica architettura che abbiamo spesso di fronte ai nostri occhi quando lavoriamo ad un gestionale. Il tutto si traduce nei seguenti passaggi: il client richiede al server un DTO, cioè in sostanza dati, li manipola e li reinvia al server il quale non dovrà far altro che identificare le modifiche fatte al DTO originario e tradurle in aggiornamenti nella base dati. I domain object, con l'avvento degli ORM, possono essere solitamente identificati negli EntityObject, nelle Tracking Instances, nei POCO o una qualsiasi altra forma supportata dall'ORM stesso. I DTO vengono spesso mappati 1-1 sul modello sottostante.
Questa architettura è stata fortemente incentivata da Microsoft con tecnologie come l'Entity Framework ed i WCF RIA Services/ADO.NET Data Services e, contrariamente a quanto si possa pensare, non ha nulla a che fare con un design di tipo Domain Driven. Qualcuno potrebbe obiettare che il modello dei dati è fortemente basato sul dominio applicativo, ma questo non è esatto per almeno due ragioni. Innanzitutto modellare le entità e lo schema del database sulla base del dominio applicativo è una conseguenza della semplicità nell'eseguire questo tipo di operazione messa a disposizione dagli ORM e non una conseguenza del voler adottare un design Domain Driven. In secondo luogo, un'architettura Domain Driven non ha nulla a che fare con le classiche operazioni di CRUD gestite dall'architettura che vi ho proposto, ma piuttosto è di tipo Task Driven, cioè espone nella UI le operazioni logiche del dominio applicativo e non quelle fisiche di persistenza sul database.
Chiaramente è possibile che Create, Update e Delete corrispondano anche ad operazioni logiche del dominio applicativo, ma di fatto normalmente quello che ci si limita a fare è recuperare i dati lato client, modificarli e lanciare una SaveChanges. Questo approccio non è un design di tipo Domain Driven ed è fatto per semplificare la vita dello sviluppatore, non per semplificare la vita dell'utente finale dell'applicazione. Volete un esempio? Pensate che, in un rubrica, recuperare dal database la riga di un contatto, esporre tutti i campi in una form, cambiare il campo "Indirizzo" e cliccare su "Salva" sia un'operazione intuitiva per chi non sa che significhi fare una INSERT, UPDATE e DELETE? E' comodo per noi sviluppatori, ma per l'utente forse sarebbe più comodo avere un pulsante denominato "Cambia indirizzo", una maschera che mostra solo l'indirizzo e un pulsante "Ok".
Al di là del voler adottare o meno un design di tipo Domain Driven, scelta più che lecita in molteplici ambiti applicativi, il problema più grande dell'architettura sopra esposta è la assoluta centralità del database nel corso della normale operatività. In tutti i casi è necessario tradurre i dati che vogliamo recuperare in una query SQL, dobbiamo quindi risolvere il problema dell'Impedance Mismatch (lo fanno per noi gli ORM, ma ha comunque un costo), tradurre il tutto in DTO, tracciare le modifiche effettuate e ritradurle un query SQL per aggiornare la base di dati. In tutto questo giro gli RDBMS devono rispettare le ACID (Atomicity, Consistency, Isolation, e Durability) e questo rappresenta un collo di bottiglia non indifferente. Sappiate, infatti, che potete anche avere due processori da 4 core l'uno e 64 GB di RAM sul vostro server, ma se vengono lanciate in parallelo tante operazioni sui medesimi dati, entreranno in gioco i meccanismi di ROW LOCK, RANGE LOCK o, peggio, TABLE LOCK, che metteranno tutte le operazioni in fila rendendo vano il vostro sforzo economico per la scalabilità verticale.
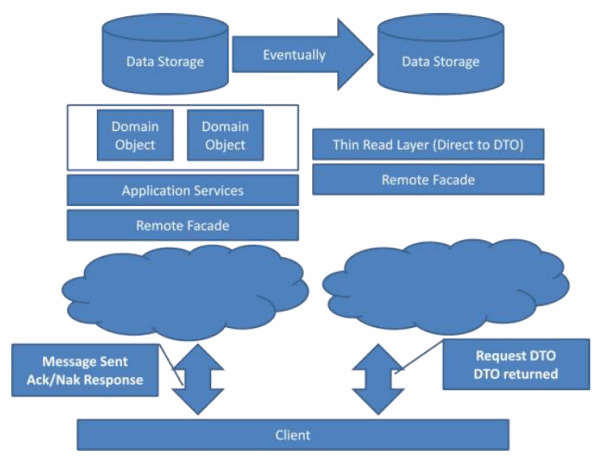
Come se ne esce dunque? Beh la Command Query Responsibility Segregation propone un diverso approccio all'architettura di un sistema al fine di risolvere questi problemi. Il concetto fondamentale è quello della separazione delle operazioni di lettura da quelle di scrittura. Questa separazione ci permette di separare anche i rispettivi modelli: se in lettura nella UI ho bisogno di denormalizzare i miei dati, cioè di unire due informazioni che nel database sono normalizzate, ma che in visualizzazione mostro insieme, per quale ragione devo forzare il sistema ogni volta che ho bisogno di questi dati in lettura ad eseguire LOCK e JOIN? La soluzione, quindi, è di separare le letture dalle scritture sia dal punto di vista del modello, che della persistenza. Ecco, quindi, che il modello concettuale, che nell'architettura classica è mappato il più possibile sul database (o, se preferite, il contrario con un approccio Code First), si scinde in due distinti modelli: il command model ed il query model. Il primo è utilizzato per invocare da parte della UI operazioni sui dati, mentre il secondo ha il solo scopo di modellare i dati nel modo più vicino possibile ai DTO richiesti dalla UI.
Non mi dilungherò eccessivamente nelle modalità operative con le quali è possibile implementare questo approccio, ma vi faccio un esempio di come adottarlo sulla piattaforma Azure: potremmo utilizzare SQL Azure come database sul quale lanciare i comandi di scrittura definiti nei vari command model inviati dal client, mentre l'Azure Table Storage è un eccellente candidato per persistere le informazioni opportunamente denormalizzate. In base all'analisi del software, potrebbe essere necessario replicare un dato presente una volta su SQL Azure, più volte nell'Azure Table Storage. Per esempio, si potrebbe voler avere uno stesso dato replicato N volte, una per ogni forma denormalizzata (o, se vogliamo, vista) richiesta dal client per accedere in lettura a quel dato. A tal proposito vi invito a non preoccuparvi eccessivamente dei costi di storage: il costo di 5 GB su SQL Azure corrisponde a 175 GB sul Table Storage.
Come qualcuno avrà certamente intuito l'implementazione di quest'architettura richiede la risoluzione di un problema: mantenere opportunamente sincronizzati i dati su SQL Azure e sull'Azure Table Storage, ma la criticità di questa problematica dipende fortemente dall'ambito applicativo. Anche se aggiornare entrambe le basi di dati (indipendentemente dalla tecnica utilizzata) è sicuramente più oneroso rispetto ad aggiornarne solo una, se per ogni scrittura di un dato, vengono effettuate più letture, ecco che il costo pagato in fase di aggiornamento sarà ampiamente controbilanciato dalla scalabilità in lettura offerta dall'Azure Table Storage.
In sostanza, maggiore è il rapporto tra le letture e le scritture, maggiore sarà il vantaggio in scalabilità potenzialmente perseguibile. Questo è sicuramente il caso dei portali web e dei social network: il numero di letture è certamente superiore, e non di poco, a quello delle scritture. Va, inoltre, considerato che non sempre è necessario un aggiornamento del dato in tempo reale. Pertanto, se è tollerabile un piccolo lasso di tempo nel quale le informazioni tra le due basi di dati non sono sincronizzate, la fase di sincronizzazione potrebbe anche essere eseguita asincronamente rispetto all'aggiornamento, rendendo quest'ultimo più rapido e non bloccante.
