Una delle diatribe più interessanti alle quali si assiste nel momento in cui ci si approccia alle tecnologie per il cloud messe a disposizione da Microsoft è quella che mette in contrapposizione SQL Azure e l'Azure Table Storage.
SQL Azure è il database relazionale marchiato Microsoft per il cloud ed essenzialmente è una versione di SQL Server che gira nei datacenter in maniera analoga alle compute instance di Windows Azure.

Trattandosi di un database relazionale, le applicazioni che si basano su SQL Server non avranno, teoricamente, grandi difficoltà nell'utilizzare SQL Azure come database. Esistono ad oggi alcune limitazioni in questa piattaforma rispetto ad un'installazione Standard o Enterprise di SQL Server, ma nel tempo molte di queste limitazioni sono state risolte. Per esempio in SQL Azure non è disponibile la ricerca fulltext, gli Analysis Services, così come le reference cross-database (cioè la possibilità di coinvolgere in una query tabelle appartenenti a database distinti), tuttavia altre deficienze presenti nel passato sono state implementate ed un esempio è rappresentato dai Reporting Services. Per maggior informazioni in merito alle funzionalità che ci piacerebbe vedere in SQL Azure vi consiglio di fare riferimento al sito dedicato.
L'Azure Table Storage, invece, fa parte, insieme ai Blob e Queue Storage, dei Windows Azure Storage Services, cioè di servizi di immagazinamento dei dati messi a disposizione da Microsoft nell'ambito della piattaforma cloud Windows Azure. Il Table Storage può essere considerato un database NoSQL. Cosa contraddistingue questo tipo di database? Beh contrariamente ai RDBMS che si basano sull'ormai robusto e collaudato modello relazionale e sul rispetto delle ACID (Atomicity, Consistency, Isolation, e Durability), i database NoSQL nascono per risolvere problematiche differenti e, in particolare, il loro focus è spesso la scalabilità orizzontale.
Supponiamo di avere un server con un'istanza di database e di renderci conto che è arrivato al suo limite massimo di prestazioni a causa del carico di lavoro. Scalare verticalmente significa aumentare la potenza di calcolo del server attraverso un aggiornamento di CPU, RAM e quant'altro contribuisca a migliorarne le prestazioni. Quest'ultimo è il classico approccio che si adotta, ma non è di certo il migliore per svariante ragioni:
- Limiti: per quanto si possano aggiornare le componenti di un server, prima o poi si raggiungerà il limite massimo della piattaforma hardware
- Costi: il prezzo dell'hardware non scala linearmente alla sua potenza, ma spesso le componenti migliori costano svarianti ordini di grandezza più delle controparti meno prestanti
- Scarso equilibrio: aggiornando l'hardware del proprio server si rischia di dimensionarlo sulla base di carichi di lavoro che possono rappresentare semplicemente dei picchi rispetto al carico standard. Chiaramente questa considerazione è fortemente dipendente del dominio applicativo, ma in linea di principio è pur sempre valida
Scalare orizzontalmente significa poter affiancare all'istanza applicativa in difficoltà, una seconda, magari su un server virtuale o fisico diverso, e vederne raddoppiare il carico di lavoro sostenibile.
I database relazionali storicamente non hanno una enorme capacità di scalare orizzontalmente, soprattutto se i dati sottoposti maggiormente agli accessi sono concentrati in alcune specifiche tabelle relazionate tra loro. Il dover sottostare al rispetto delle ACID, comporta il lock dei dati alla loro modifica al fine di conservare la consistenza del dato. La problematica diventa ancor più stringente nel momento in cui si fanno uso di transazioni che coinvolgono parecchie righe e tabelle.
SQL Azure mette a disposizione alcune funzionalità per migliorare la scalabilità:
- Distribuire i dati su più database ne garantisce la scalabilità orizzonale perché database SQL Azure distinti possono essere distribuiti su server differenti. Chiaramente ciò limita la possibilità di fare
- Database Sharding: è una tecnica che consente in sostanza di partizionare i propri dati in base ad una serie di criteri (ID, Range di ID, ecc...) al fine di distribuirli automaticamente su più database e, quindi, ottenere la scalabilità orizzonale nel caso in cui le query siano distribuite più o meno equamente su tutti i database
Con queste tecniche si può ottenere la scalabilità anche su un database relazionale on the cloud come SQL Azure, ma è possibile che ciò non sia sufficiente. Supponiamo di avere a che fare con un ambito applicativo nel quale abbiamo tantissimi dati in tabelle per le quali non è possibile effettuare lo sharding, cioè distribuirle su più database in base ad una chiave o ad una range di chiavi o che comunque, anche se possibile, non trarrebbe alcun beneficio da questa soluzione perché magari a livello di SELECT si deve accedere quasi sempre ai dati in maniera globale.
Un altra situazione nel quale la scalabilità orizzontale di SQL Azure può comunque non essere sufficiente è rappresentata dai costi: 5 GB su SQL Azure costano circa € 35, mentre con la medesima cifra è possibile ottenere 325 GB su Table Storage con 4 milioni di transazioni al mese.
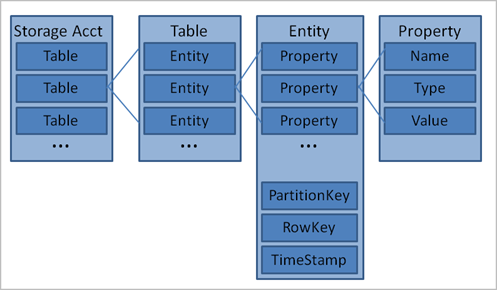
Esistono svariati tipi di database NoSQL e il Table Storage di Windows Azure può essere considerato di tipo "Key-Value". In pratica è possibile definire tabelle in ognuna delle quali ogni riga è univocamente identificata da una RowKey ed una PartitionKey, la cui coppia essenzialmente è la chiave primaria. Ogni riga può avere fino a 255 proprietà o colonne e non può contenere complessivamente più di 1 MB di dati.
Nel processo di ingegnerizzazione di un software destinato ad usare il Table Storage è fondamentale scegliere accuratamente la RowKey e la PartitionKey. Quest'ultima in particolare rappresenta il partizionamento dei dati: tutti i dati di una partizione si trovano sul medesimo server e, quindi, sarebbe opportuno sceglierla in maniera che le interrogazioni del software siano uniformemente distribuite su tutte le partition key per massimizzarne le performance.
Un altro aspetto interessante è la replicazione automatica dai dati in tre copie nel medesimo datacenter e in due datacenter del medesimo continente. Questa caratteristica garantisce sia una maggiore fault tolerance, sia maggiori performance di accesso in lettura ai dati stessi.
Non è obiettivo di questo post fornire un HOW-TO delle operazioni di interrogazione su Table Storage, ma vi posso anticipare che è possibile sia farlo mediante banali richieste HTTP REST, che attraverso le comodissime API WCF Data Services che consentono di eseguire query anche mediante LINQ.
Chiaramente non sono tutte rose e fiori: il servizio di Table Storage, infatti, non è un database relazionale e, pertanto, non vi consente di eseguire query mettendo in join più tabelle. Questa operazione è possibile eseguirla solo client side, cioè scaricando sul client i contenuti di entrambe le tabelle e mettendole in join con LINQ to Objects, ma chiaramente questa non è una soluzione ottimale da nessun punto di vista. La realtà è che se si intende far lavorare questo tipo di servizio come se fosse un database relazionale, si otterranno risultati molto poco soddisfacenti.
Le interrogazioni su Table Storage sono molto efficienti a patto che il filtro coinvolga prevalentemente la RowKey e la PartitionKey. Qualsiasi altro uso comporterà quello che in ambito RDBMS chiameremmo un FULL SCAN e cioè qualcosa da evitare assolutamente.
Limitazioni esistono anche nell'uso delle transazioni: queste sono supportate solo se coinvolgono non solo righe appartenenti da una sola tabella, ma devono far riferimento ad una stessa partizione di quella tabella.
E' chiaro, quindi, che non è possibile pensare di migrare un sistema da SQL Server al Table Storage senza dover riprogettare interamente lo strato di accesso ai dati. E' necessario progettare l'architettura del software con l'obiettivo di sfruttare tutti i punti di forza del Table Storage, chiaramente laddove l'ambito applicativo lo consenta e, soprattutto, ne tragga beneficio.
I più scettici e i più grandi sostenitori del modello relazionale sicuramente avranno già cestinato l'idea di utilizzare il servizio di Table Storage, ma vi posso assicurare che è possibile sfruttare un database non relazionale con successo e grandi soddisfazioni e social network come Facebook e Twitter sono esempi evidenti dell'uso di database NoSQL in ambiti applicativi dove la scalabilità ha la priorità su tutto, scalabilità che non si sarebbe mai raggiunta affidandosi solo ai cari vecchi database relazionali.
Il prossimo post vi parlerò di un'architettura ideata proprio con l'obiettivo di trarre il massimo beneficio da database come il Table Storage.
